|
|
|
研究は主として、バイオ系、IT系の2つで実施した。以下に主な成果を示す。
・ 研究概要:バイオ系
- ディスオーダー領域を考慮したタンパク質結晶化予測
タンパク質の立体構造を解析する手段として最も多く用いられているX 線結晶解析において、
タンパク質結晶化は必要不可欠な工程となっている。しかし、すべてのタンパク質が簡単に結
晶化するわけではなく、結晶化の条件を求め、タンパク質の結晶を得るまでに時間や費用が十
分に必要である。すなわち、タンパク質結晶化がX 線結晶解析のボトルネックとなっている。
そこで、生物学的実験を行う前に結晶化するタンパク質を特定することができれば実験にかか
る時間や費用の削減につながる。現在、タンパク質結晶化を予測する研究では、アミノ酸組成、
疎水性、等電点が利用されている。加えて、結晶化に影響を与えるようなタンパク質立体構造
情報を利用することで精度の向上が予想されることから、本研究ではタンパク質立体構造情報
を利用したタンパク質結晶化予測法を提案する。本研究ではタンパク質立体構造としてディス
オーダーを利用する。結晶化を阻害すると報告されているディスオーダーが結晶化しづらくす
る因子として役立つと考え、タンパク質結晶化予測の精度向上を図った。その結果、Accuracy
が75.7%となった。また、アミノ酸配列におけるディスオーダーの割合からディスオーダーが
タンパク質の結晶化を阻害していることが確認された。
- GPCR リガンドの結合予測
G タンパク質共役型受容体(GPCR)は創薬研究の中心となっており,GPCR と相互作用す
る未知のリガンドを予測することは重要な課題である.しかしながら,相互作用するリガンド
が全く知られていないGPCR も多く存在し,これらのGPCR と相互作用するリガンドを予測
することは学習用サンプルの不足から困難となる.そこで,我々はサポートベクターマシンを
利用した2-way prediction 法を提案した.この方法では,リガンド,GPCR,双方から予測を
行い,相互作用するリガンドの情報とGPCR の情報が全くない場合の予測に対応し,実験に
より提案手法の有効性を示した。
・ 研究概要:IT系
- 検索エンジンの信頼性解析
本研究では,検索エンジンのヒット数に対する信頼性の検証を行った.ここでヒット数とは,
検索エンジンが返すクエリに一致するドキュメント数を指す.ヒット数を利用することで,Web
上においてクエリキーワードがどの程度利用されているか容易に取得することができるため,
ヒット数は様々な研究で利用されている。一方で,ヒット数は様々な状況において変化するこ
とが確認されており,ヒット数の信頼性を明らかにすることが必要不可欠となってきている.
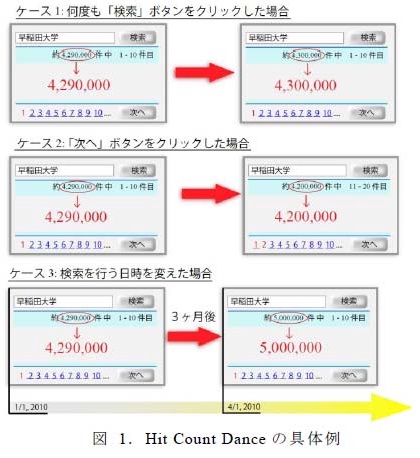
ヒット数は,(1)短時間に繰り返し検索を行った場合,(2)検索開始オフセットを変化さ
せた場合,(3)検索を行う日時が変わった場合,に変化する。このようにヒット数が変化し
た場合,どのような状況下のヒット数がより信頼できるか明らかではない.そこで,本研究で
はヒット数が変化をするケースを上記の3 つに分類し,それぞれのケースに対して信頼性を検
証した.その結果として,信頼できるヒット数は「検索開始オフセットが最も大きい場合に得
られるヒット数で,かつ,検索エンジンによってヒット数の調整が行われていない場合」かつ
「時間経過による変化が1週間以上安定している場合」に得られることを確認した。
- 解析のためのWeb グラフ圧縮手法に関する研究
Web グラフを圧縮しグラフデータのサイズを削減することで,データの運用およびリンク解
析アルゴリズムを実行する際に必要となる計算資源や計算時間などを削減することが可能であ
る.Web グラフの圧縮に関しては,これまでVirtual Node Miner と呼ばれる可逆圧縮手法が
提案されているが,ノード数については圧縮ができなかった。これに対して本研究では,非可
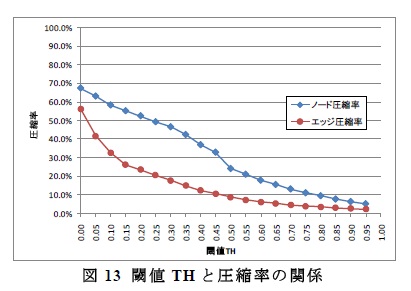
逆圧縮によってノード数,エッジ数共に圧縮するWeb グラフ圧縮手法LittleWeb を提案した。
LittleWeb ではWeb グラフ上のノードを類似度によってクラスタリングし集約することで,
Web グラフのノード・エッジを削減しグラフサイズを縮小する.実際にLittleWeb を用いるこ
とによって,Web クローリングによって得られたノード数39,459,925,エッジ数936,364,282
のWeb グラフに対し,ノード圧縮率52.4%,エッジ圧縮率23.5%という圧縮率が得られた。ま
たLittleWeb により圧縮されたグラフは解凍することなくリンク解析アルゴリズムを実行でき
るため, PageRank の計算時間を67%削減することに成功した。
・ 講演会等
- 2009年4月 見学会 場所:産総研生命情報科学研究センター
・ 受賞
- 2009年6月 山名早人、IBM Faculty Award
- 2009年6月 山名早人、日本データベース学会2008年度論文賞
・ 報道等
- 2009年6月18日 山名早人、近未来型“計算知識エンジン”ウルフラムアルファの頭脳、 R25.jp
- 2009年7月17日 山名早人、検索新技術「巨人に挑む」、朝日新聞、2009.7.17,18 面
- 2009年8月4日 山名早人、検索サービスはGoogle を超えた!?、日経トレンディ2009年9月号、pp.134-139
・ 受託研究
- 日本電気株式会社より「大規模Web 情報分析システムの研究」
- パナソニック株式会社より「AV コンテンツの高精度検索に関する研究」
- 有限会社USP 研究所より「パイプライン計算機のデータ流路最適化」
- JSTより「多メディアWeb解析基盤の構築及び社会分析ソフトウェアの開発」
・論文等はこちら⇒ 2009年度論文.pdf
|
