|
|
|
研究は主として、バイオ系、IT系の2つで実施した。以下に主な成果を示す。
・ 研究概要:バイオ系
- 進化的計算手法を用いた遺伝子ネットワーク推定システムの設計・開発
2008 年度は、成功率(精度)を向上させるために、複数のデータ系列を与え、それらを同時に再現す
る方程式を推定した場合、推定するネットワークの規模が大きくなるにつれ、最適化対象となる解空
間(探索空間)が広くなり、最適化効率・精度が悪くなってしまう問題の解決を図った。
提案手法とは、最適化の初期段階において、数理モデルに質量作用則表記の近似式であるS-system
表記の微分方程式、最適化手法に遺伝的アルゴリズム(GA)を用いて、ネットワークの概略を高速に導
出し、その結果を拘束条件とすることで最適化対象の解空間の絞り込みを行い、これまでの手法(質
量作用則+遺伝的プログラミング(GP))で詳細なネットワーク構造を導出するハイブリッド数理モデ
ル手法である。本研究にハイブリッド数理モデル手法を採り入れてプロトタイプシステムを開発し、
有効性の検証を行った。50 試行中46 試行で最適化が成功し、ハイブリッド数理モデル手法の有効性
を示すことができた。
さらに、従来手法のシステムと同様に、複数のデータ系列を与え、それらを同時に再現する方程式
を推定できるようにシステムを改良し、与えたデータ系列を増やすことによって、成功率(精度)が向
上するか調べた。また、計算時間については、計算時間の短縮を図るため、グリッド環境下での利用
を想定した並列化を行い、同一クラスタ内での疑似グリッド環境下でスケーラビリティを検証したと
ころ、高いスケーラビリティを示すことができた。
- 創薬支援のための膜タンパク質配列─立体構造情報の統合データベースの構築
タンパク質を「理解」するためには、アミノ酸配列・機能・構造の相関を得ることが重要である。
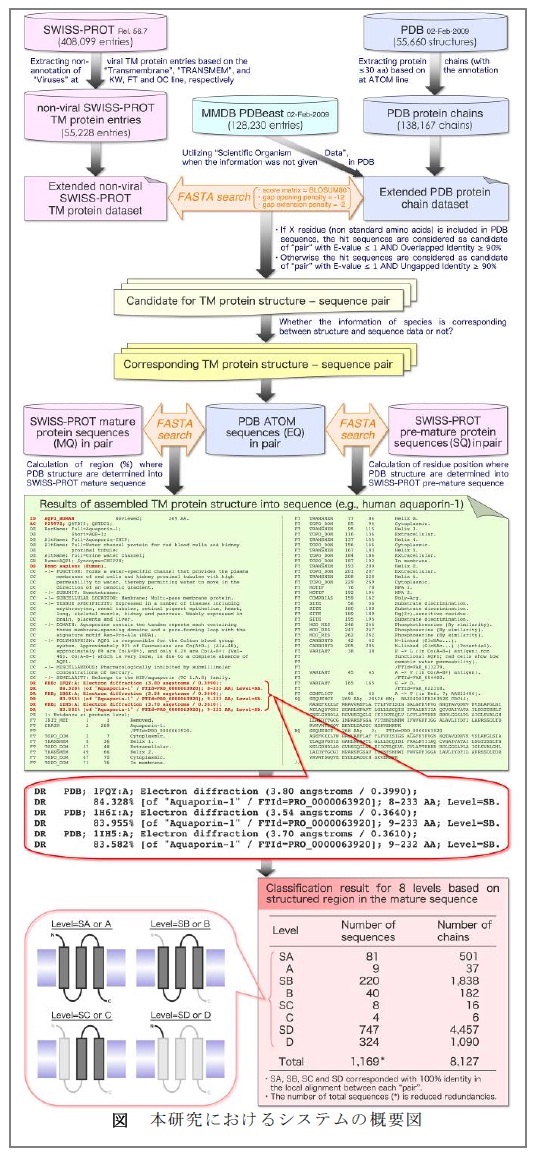 そこで、国際標準であるSWISS-PROT(タンパク質名・機能・細胞内局在・翻訳後修飾・
アミノ酸配列などの基本情報が整理された公共データベース)と、PDB(生体高分子の立
体構造の原子座標と、その構造が得られた際の実験方法・解像度・アミノ酸/核酸配列など
が格納された公共データベース)に登録されている各エントリー情報を統合する(帰属す
る)システムを設計・開発する必要がある。また、これらのデータベースはそれぞれ頻繁
に更新を行うため、情報統合のステップをできる限り短時間かつ簡便に行う必要がある。
さらに、この中から機能異常が重篤な疾病を引き起こすため創薬分野における研究開発に
おける重要なターゲットであり、細胞活動の重要な機能を担っている膜タンパク質の配列
と立体構造を帰属するシステムの設計・開発を行った。
そこで、国際標準であるSWISS-PROT(タンパク質名・機能・細胞内局在・翻訳後修飾・
アミノ酸配列などの基本情報が整理された公共データベース)と、PDB(生体高分子の立
体構造の原子座標と、その構造が得られた際の実験方法・解像度・アミノ酸/核酸配列など
が格納された公共データベース)に登録されている各エントリー情報を統合する(帰属す
る)システムを設計・開発する必要がある。また、これらのデータベースはそれぞれ頻繁
に更新を行うため、情報統合のステップをできる限り短時間かつ簡便に行う必要がある。
さらに、この中から機能異常が重篤な疾病を引き起こすため創薬分野における研究開発に
おける重要なターゲットであり、細胞活動の重要な機能を担っている膜タンパク質の配列
と立体構造を帰属するシステムの設計・開発を行った。
本研究では、以下の3つの公的データベースを各々の運営FTPサイトからダンウンロードして使用した。
- SWISS-PROT ( release 56.7 of 20-Jan-2009; 408,099 entries)[1 ファイル / 1.65GB]
- PDB ( release 09-Feb-2009; 55,660 macromolecules; 138,167 protein chains)[55,660 ファイル / 36.7GB]
- MMDB PDBeast(release 05-Feb-2009;128,230 entries)[1 ファイル / 7.1MB]
計算機は主に、独立行政法人 産業技術総合研究所 生命情報工学研究センターが管理・運
用している並列計算機Magi システム(CPU:Pentium III 933MHz Dual×1040、
RAM:1GB×520、HDD:19152GB)を利用した。また、全てのプログラミングはスク
リプト言語Perl で記述し、オブジェクト化することによって拡張性を確保している。
アミノ酸配列データベースSWISS-PROT配列エントリーと生体高分子立体構造データ
バンクPDB 構造チェインとを帰属させるために作成したプログラムのフローを右図に示す。
処理は9 つのステップを逐次的に行う。特に、昨年度下半期から帰属システムのプログラムの改良を行った。
主な改良点は以下の3点である。
- PDB に誤ったフォーマットで登録されているエントリーへの対応。
- 生物種名が記載されていないPDB チェインに対してMMDB PDBeast からの生物種名に関す
るアノテーションの抽出・引用。
- 人工的改変タンパク質構造エントリーへの改変前状態へのアミノ酸配列情報の操作。
プログラムを実行した結果をフローの図の下側、および円図にまとめる。SWISS-PROT(release
56.7)に登録されている配列エントリーは408,099 であるが、非ウイルス由来の膜タンパク質は
55,228(13.5%)エントリーであった。このうち、構造が既知であるものは僅か1,169 エントリー
(2.1%)であることが分かった。
膜貫通領域に関して構造決定範囲およびアミノ酸置換割合に基づき8 つに分類した結果、
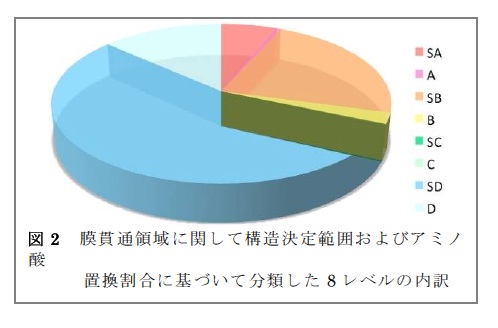 成熟タンパク質のN 末端からC 末端までのほぼ全領域が構造決定されてい
るもの(レベルSA、A)は90 エントリー / 838 チェインであった。
また、全ての膜貫通領域を含み、
N末端もしくはC末端の一部を除いて構造決定されているもの(レベルSB、B)は260 エントリ
ー / 2,020 チェインである。その他のレベルSC、C、SD、D は断片的な構造であり、合計1,083 エ
ントリー / 5,569 チェインであった。つまり、計算化学におけるシミュレーション(分子動力学
法、分子軌道法など)の利用に耐えうる立体構造データは、現状では僅かである。しかしながら、
将来、膜タンパク質結晶化技術が向上した際、本手法によってシミュレーションに利用な可能な
立体構造データを容易に収集することが可能である。
成熟タンパク質のN 末端からC 末端までのほぼ全領域が構造決定されてい
るもの(レベルSA、A)は90 エントリー / 838 チェインであった。
また、全ての膜貫通領域を含み、
N末端もしくはC末端の一部を除いて構造決定されているもの(レベルSB、B)は260 エントリ
ー / 2,020 チェインである。その他のレベルSC、C、SD、D は断片的な構造であり、合計1,083 エ
ントリー / 5,569 チェインであった。つまり、計算化学におけるシミュレーション(分子動力学
法、分子軌道法など)の利用に耐えうる立体構造データは、現状では僅かである。しかしながら、
将来、膜タンパク質結晶化技術が向上した際、本手法によってシミュレーションに利用な可能な
立体構造データを容易に収集することが可能である。
・ 研究概要:IT系
- 肖像権侵害ブログの検出
近年,ブログ記事の増加に伴い,人物画像の無断使用が増えている.これらを手動で探すこ
とは困難なため,画像検索の研究が盛んに行われている.しかし,ブログを対象とした場合,
画像以外の情報も使用した方が高い精度を得られる可能性がある.また,画像単位ではなくブ
ログ単位で侵害度合を得ることは有用である。
そこで,本研究では人物画像を無断で使用しているブログを,ブログ単位で自動的に検出す
る手法を提案した.本手法は,記事の投稿間隔が短く偏りが大きいほど侵害度合が高いと仮定
する点と,ブログごとの侵害度合を定量化できる点が特徴である.実験では,画像の無断使用
をしているブログとしていないブログを予め人手で用意し,それぞれに対して提案手法を用い
た.侵害ブログと非侵害ブログをそれぞれ10 件ずつ用いた実験を13 人分行った結果,F 値が
0.728 となり,画像のみを使った手法に比べて0.011 向上させることができた。
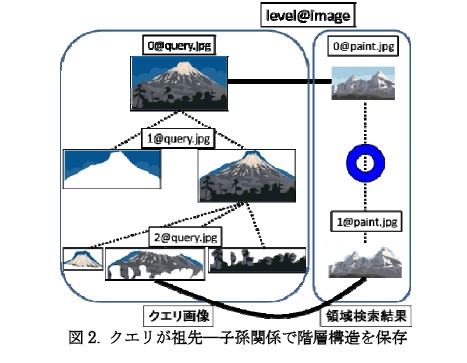
- 画像検索
類似画像検索手法として,画像を意味のある領域に分割し,類似した領域を多く持つ画像同
士を類似した画像とみなす,領域ベースの検索が広く行われている.しかし,例えば人が写っ
ている画像を分割する際,人全体を一つの領域と捉えるか,目,帽子,髪等の部分をそれぞれ
別の領域と捉えるかは,アプリケーションの目的や画像を見た人の主観によって異なる.この
画像分割の一意性の問題に対し,画像を階層的に分割することでより多様な画像領域を抽出す
る手法が提案されている.階層的画像分割では,画像全体をルートノード,画像を分割して得
られた領域をルートの子ノードとし,更に子ノードにおいてもルートノードに行ったのと同様
の分割を再帰的に行うことで,画像全体の分割結果をグラフ構造によって表現する。
本研究では,この階層的画像分割を利用した類似画像検索手法を提案した.提案手法では,
グリッド分割ではなく,画像毎に適応的な任意形状の領域に画像を分割する手法を用い,更に
領域同士の階層的構造を考慮して画像同士の類似度を計算する.提案手法により,階層構造を
保存した画像同士の類似度が高くなり,高精度な検索を実現できた。
・ 講演会等
- 2008年4月 見学会 場所:産総研生命情報科学研究センター
- 2008年5月24日 連携大学院説明会 場所:産総研生命情報科学研究センター
- 2008年10月1日 ITバイオ研究所セミナー 場所:早稲田大学
「プロファイルを利用したタンパク質機能部位の解析」
・ 報道等
- 2008年4月23日 InternetWatch 「百度と早稲田大学で産学連携」
- 2008年11月3日 山名早人、過去のサイトを検索できるWEBアーカイブの魅力,、R25.jp
・ 受託研究
- 富士通研究所より「分散知識の再構成・活用技術」
- 百度株式会社より「Web リソースの収集解析および画像検索」
- パナソニック株式会社より「A V コンテンツの高精度検索に関する研究」
・論文等はこちら⇒ 2008年度論文.pdf
|
